目标
具体实现
(一)环境
语言环境:Python 3.10
编 译 器: PyCharm
框 架: Pytorch
(二)具体步骤
1. Utils.py
import torch
import pathlib
import matplotlib.pyplot as plt
from torchvision.transforms import transforms
# 第一步:设置GPU
def USE_GPU():
if torch.cuda.is_available():
print('CUDA is available, will use GPU')
device = torch.device("cuda")
else:
print('CUDA is not available. Will use CPU')
device = torch.device("cpu")
return device
temp_dict = dict()
def recursive_iterate(path):
"""
根据所提供的路径遍历该路径下的所有子目录,列出所有子目录下的文件
:param path: 路径
:return: 返回最后一级目录的数据
""" path = pathlib.Path(path)
for file in path.iterdir():
if file.is_file():
temp_key = str(file).split('\\')[-2]
if temp_key in temp_dict:
temp_dict.update({temp_key: temp_dict[temp_key] + 1})
else:
temp_dict.update({temp_key: 1})
# print(file)
elif file.is_dir():
recursive_iterate(file)
return temp_dict
def data_from_directory(directory, train_dir=None, test_dir=None, show=False):
"""
提供是的数据集是文件形式的,提供目录方式导入数据,简单分析数据并返回数据分类
:param test_dir: 是否设置了测试集目录
:param train_dir: 是否设置了训练集目录
:param directory: 数据集所在目录
:param show: 是否需要以柱状图形式显示数据分类情况,默认显示
:return: 数据分类列表,类型: list
""" global total_image
print("数据目录:{}".format(directory))
data_dir = pathlib.Path(directory)
# for d in data_dir.glob('**/*'): # **/*通配符可以遍历所有子目录
# if d.is_dir():
# print(d) class_name = []
total_image = 0
temp_sum = 0
if train_dir is None or test_dir is None:
data_path = list(data_dir.glob('*'))
class_name = [str(path).split('\\')[-1] for path in data_path]
print("数据分类: {}, 类别数量:{}".format(class_name, len(list(data_dir.glob('*')))))
total_image = len(list(data_dir.glob('*/*')))
print("图片数据总数: {}".format(total_image))
else:
temp_dict.clear()
train_data_path = directory + '/' + train_dir
train_data_info = recursive_iterate(train_data_path)
print("{}目录:{},{}".format(train_dir, train_data_path, train_data_info))
temp_dict.clear()
test_data_path = directory + '/' + test_dir
print("{}目录:{},{}".format(test_dir, test_data_path, recursive_iterate(test_data_path)))
class_name = temp_dict.keys()
if show:
# 隐藏警告
import warnings
warnings.filterwarnings("ignore") # 忽略警告信息
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.rcParams['figure.dpi'] = 100 # 分辨率
for i in class_name:
data = len(list(pathlib.Path((directory + '\\' + i + '\\')).glob('*')))
plt.title('数据分类情况')
plt.grid(ls='--', alpha=0.5)
plt.bar(i, data)
plt.text(i, data, str(data), ha='center', va='bottom')
print("类别-{}:{}".format(i, data))
temp_sum += data
plt.show()
if temp_sum == total_image:
print("图片数据总数检查一致")
else:
print("数据数据总数检查不一致,请检查数据集是否正确!")
return class_name
def get_transforms_setting(size):
"""
获取transforms的初始设置
:param size: 图片大小
:return: transforms.compose设置
""" transform_setting = {
'train': transforms.Compose([
transforms.Resize(size),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
'test': transforms.Compose([
transforms.Resize(size),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
}
return transform_setting
# 训练循环
def train(dataloader, device, model, loss_fn, optimizer):
size = len(dataloader.dataset) # 训练集的大小
num_batches = len(dataloader) # 批次数目, (size/batch_size,向上取整)
train_loss, train_acc = 0, 0 # 初始化训练损失和正确率
for X, y in dataloader: # 获取图片及其标签
X, y = X.to(device), y.to(device)
# 计算预测误差
pred = model(X) # 网络输出
loss = loss_fn(pred, y) # 计算网络输出和真实值之间的差距,targets为真实值,计算二者差值即为损失
# 反向传播
optimizer.zero_grad() # grad属性归零
loss.backward() # 反向传播
optimizer.step() # 每一步自动更新
# 记录acc与loss
train_acc += (pred.argmax(1) == y).type(torch.float).sum().item()
train_loss += loss.item()
train_acc /= size
train_loss /= num_batches
return train_acc, train_loss
def test(dataloader, device, model, loss_fn):
size = len(dataloader.dataset) # 测试集的大小
num_batches = len(dataloader) # 批次数目, (size/batch_size,向上取整)
test_loss, test_acc = 0, 0
# 当不进行训练时,停止梯度更新,节省计算内存消耗
with torch.no_grad():
for imgs, target in dataloader:
imgs, target = imgs.to(device), target.to(device)
# 计算loss
target_pred = model(imgs)
loss = loss_fn(target_pred, target)
test_loss += loss.item()
test_acc += (target_pred.argmax(1) == target).type(torch.float).sum().item()
test_acc /= size
test_loss /= num_batches
return test_acc, test_loss
2. config.py
import argparse
def get_options(parser=argparse.ArgumentParser()):
parser.add_argument('--workers', type=int, default=0, help='Number of parallel workers')
parser.add_argument('--batch-size', type=int, default=32, help='input batch size, default=32')
parser.add_argument('--lr', type=float, default=1e-4, help='learning rate, default=0.0001')
parser.add_argument('--epochs', type=int, default=50, help='number of epochs')
parser.add_argument('--seed', type=int, default=112, help='random seed')
parser.add_argument('--save-path', type=str, default='./models/', help='path to save checkpoints')
opt = parser.parse_args()
if opt:
print(f'num_workers:{opt.workers}')
print(f'batch_size:{opt.batch_size}')
print(f'learn rate:{opt.lr}')
print(f'epochs:{opt.epochs}')
print(f'random seed:{opt.seed}')
print(f'save_path:{opt.save_path}')
return opt
if __name__ == '__main__':
opt = get_options()
**3.**main.py
from torch import nn
from torchvision import datasets
from Utils import USE_GPU, data_from_directory, get_transforms_setting, train, test
import torch
import os, PIL, pathlib
from model import Model_Shoes
import config
opt = config.get_options()
print(opt)
device = USE_GPU()
DATA_DIR = './data/hollywood'
classNames = data_from_directory(DATA_DIR)
print(list(classNames))
transforms_setting = get_transforms_setting([224, 224])
total_data = datasets.ImageFolder(DATA_DIR, transforms_setting['train'])
print(total_data.class_to_idx)
train_size = int(0.8 * len(total_data))
test_size = len(total_data) - train_size
train_dataset, test_dataset = torch.utils.data.random_split(total_data, [train_size, test_size])
print(train_dataset, test_dataset)
batch_size = opt.batch_size
train_dl = torch.utils.data.DataLoader(train_dataset,
batch_size=batch_size,
shuffle=True
)
test_dl = torch.utils.data.DataLoader(test_dataset,
batch_size=batch_size,
shuffle=True)
for X, y in test_dl:
print("Shape of X [N, C, H, W]: ", X.shape)
print("Shape of y: ", y.shape, y.dtype)
break
# 调用官方VGG16模型
from torchvision.models import vgg16
device = "cuda" if torch.cuda.is_available() else "cpu"
print("Using {} device".format(device))
# 加载预训练模型,并且对模型进行微调
model = vgg16(pretrained=True).to(device) # 加载预训练的vgg16模型
for param in model.parameters():
param.requires_grad = False # 冻结模型的参数,这样子在训练的时候只训练最后一层的参数
# 修改classifier模块的第6层(即:(6): Linear(in_features=4096, out_features=2, bias=True))
# 注意查看我们下方打印出来的模型
model.classifier._modules['6'] = nn.Linear(4096, len(classNames)) # 修改vgg16模型中最后一层全连接层,输出目标类别个数
model.to(device)
print(model)
learn_rate = 1e-4 # 初始学习率
# 调用官方动态学习率接口时使用
lambda1 = lambda epoch: 0.92 ** (epoch // 4)
optimizer = torch.optim.SGD(model.parameters(), lr=learn_rate)
scheduler = torch.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda=lambda1) #选定调整方法
import copy
loss_fn = nn.CrossEntropyLoss() # 创建损失函数
epochs = 40
train_loss = []
train_acc = []
test_loss = []
test_acc = []
best_acc = 0 # 设置一个最佳准确率,作为最佳模型的判别指标
for epoch in range(epochs):
model.train()
epoch_train_acc, epoch_train_loss = train(train_dl, device, model, loss_fn, optimizer)
scheduler.step() # 更新学习率(调用官方动态学习率接口时使用)
model.eval()
epoch_test_acc, epoch_test_loss = test(test_dl, device, model, loss_fn)
# 保存最佳模型到 best_model if epoch_test_acc > best_acc:
best_acc = epoch_test_acc
best_model = copy.deepcopy(model)
train_acc.append(epoch_train_acc)
train_loss.append(epoch_train_loss)
test_acc.append(epoch_test_acc)
test_loss.append(epoch_test_loss)
# 获取当前的学习率
lr = optimizer.state_dict()['param_groups'][0]['lr']
template = 'Epoch:{:2d}, Train_acc:{:.1f}%, Train_loss:{:.3f}, Test_acc:{:.1f}%, Test_loss:{:.3f}, Lr:{:.2E}'
print(template.format(epoch + 1, epoch_train_acc * 100, epoch_train_loss,
epoch_test_acc * 100, epoch_test_loss, lr))
# 保存最佳模型到文件中
PATH = './best_model.pth' # 保存的参数文件名
torch.save(model.state_dict(), PATH)
print('Done')
import matplotlib.pyplot as plt
#隐藏警告
import warnings
warnings.filterwarnings("ignore") #忽略警告信息
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.rcParams['figure.dpi'] = 100 #分辨率
from datetime import datetime
current_time = datetime.now() # 获取当前时间
epochs_range = range(epochs)
plt.figure(figsize=(12, 3))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, train_acc, label='Training Accuracy')
plt.plot(epochs_range, test_acc, label='Test Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.xlabel(current_time) # 打卡请带上时间戳,否则代码截图无效
plt.subplot(1, 2, 2)
plt.plot(epochs_range, train_loss, label='Training Loss')
plt.plot(epochs_range, test_loss, label='Test Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()
from PIL import Image
classes = list(total_data.class_to_idx)
def predict_one_image(image_path, model, transform, classes):
test_img = Image.open(image_path).convert('RGB')
plt.imshow(test_img) # 展示预测的图片
test_img = transform(test_img)
img = test_img.to(device).unsqueeze(0)
model.eval()
output = model(img)
_, pred = torch.max(output, 1)
pred_class = classes[pred]
print(f'预测结果是:{pred_class}')
# 预测训练集中的某张照片
predict_one_image(image_path='./data/hollywood/Angelina Jolie/003_57612506.jpg',
model=model,
transform=transforms_setting['train'],
classes=classes)
best_model.eval()
epoch_test_acc, epoch_test_loss = test(test_dl, best_model, loss_fn)
print(epoch_test_acc, epoch_test_loss)
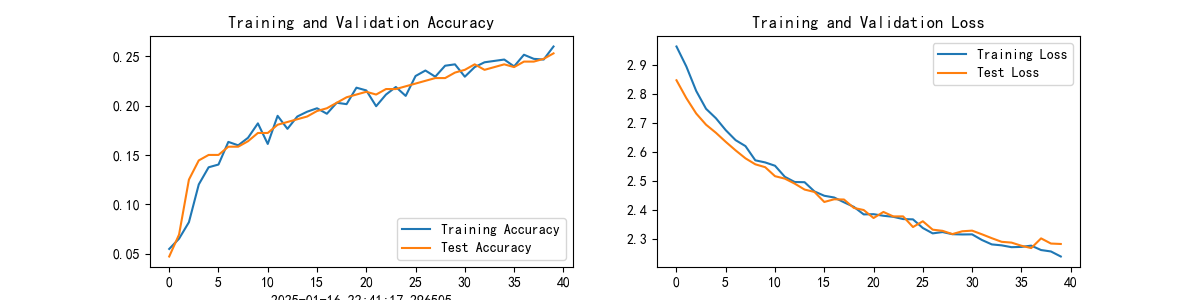
结果:Test_acc:18.9%
(三)总结
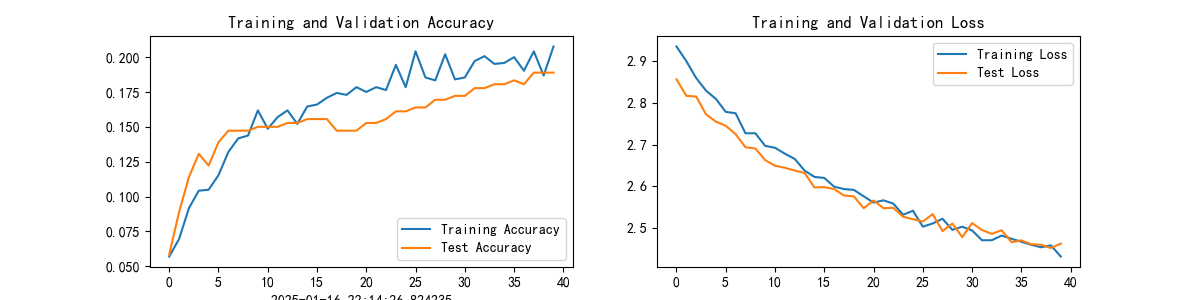
- 超参数:batch_size=64, epoches=50 结果:Test_acc:16.1%
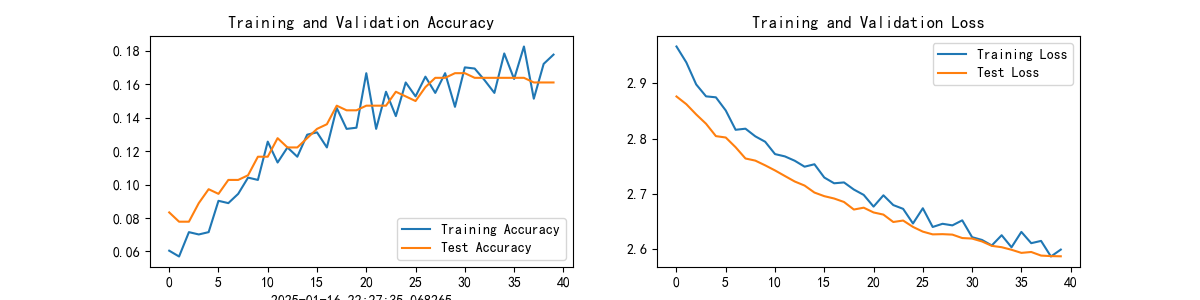
- 修改学习率:0.0002 结果:Test_acc:25.3%